

Hello again
This time I want to tell you about the broken links hijacking technique which I decided to give a chance after reading some blog posts about it. The whole process consists of grabbing all the external links from the site and checking if they point to either non-existent (NXDOMAIN) or to some domain where we can take over the account (ie. Twitter profile). We are interested only in external links as if we scan https://example.com, we cannot control links on https://example.com except the subdomains of example.com which can be taken over.
The tools
There are several online tools that I used at the beginning in the process of scanning:
https://www.deadlinkchecker.com/website-dead-link-checker.asp
https://www.brokenlinkcheck.com
These tools are free but have limitations – they check only up to 2000 links and can’t exclude the internal ones. That’s why I decided to look for some console tools and I stumbled on this tool:
https://www.npmjs.com/package/broken-link-checker
You can install this tool using the npm package manager. The tool allows you to exclude internal links and also has several filtering options. You can choose the level of searching:
- clickable links
- clickable links, media, iframes, meta refreshes
- clickable links, media, iframes, meta refreshes, stylesheets, scripts, forms
- clickable links, media, iframes, meta refreshes, stylesheets, scripts, forms, metadata
I used this command to gather all broken links from the site example.com:
$ blc -r –filter-level 2 -i https://example.com –user-agent “Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/109.0” | grep BROKEN | tee -a broken_links
The -r option scans the site recursively, which means if it finds the link pointing to https://helloworld.example.com on https://example.com , it will follow it and starts checking all the links on this site. This makes the process much slower, however, it is the only way to scan all the links on the site. The problem with this is when for example the site has several sections and the footer which has some links pointing outside. In this case, all the sections are being scanned, and also the links in the footer – over and over again. The way of doing it would be to gather all links first, deduplicate them and scan all the unique ones.
We are mainly interested in links that return some kind of ERROR , especially ERRNO_ENOTFOUND – this usually indicates the domain does not exist. The statuses like 500,404,403,999 indicate the links are not broken and we cannot take them over.
The first finding
I run my script and when it finished, I analyzed the output file. I found two ERRNO_ENOTFOUND entries – the first one pointed to the domain someexpireddomain.com. I examined the domain with dig it to confirm it is the non-existent domain.
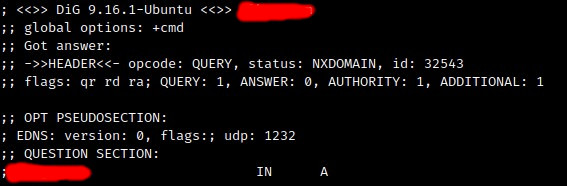
Then I went to https://ovh.com and checked if I can buy the domain, and yes I could – so I reported the issue. The link was removed and I was rewarded 100$ for this.
The second finding – the CDN takeover
The second finding was more interesting. This was a subdomain of azureedge.net.
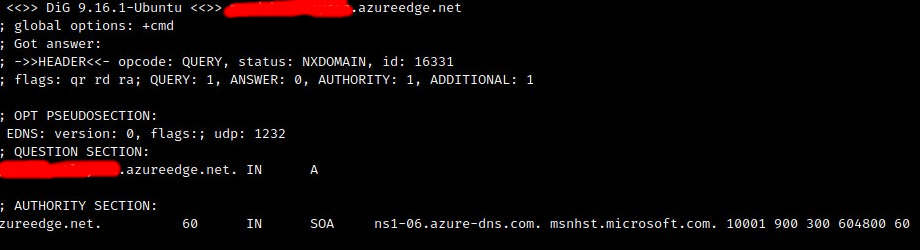
I am not an azure specialist so I googled a bit and this domain is Microsoft Azure CDN service. I logged in to my azure account, selected “Front doors and CDN profiles”, then “Explore other offers” and “Azure CDN Standard”, then checked if I can create the profile. I saw the green tick which made me very happy. Sometimes even if dig shows NXDOMAIN status, it cannot be taken over.
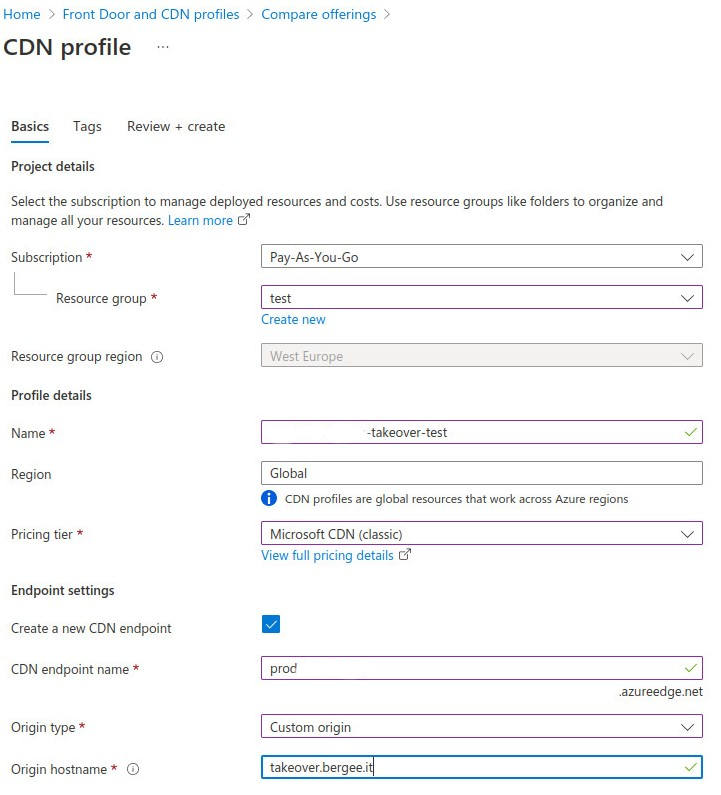
I set the origin hostname to my subdomain to create the POC. Now I needed to also create the endpoint for the CDN, which is the files will be served from. This endpoint can be edited if you enter the CDN profile and the “Sources”. There you can edit the source for the endpoint. I don’t have the screenshot, unfortunately. After these steps, the prodcdnexample.azureedge.net was taken over and I could serve the file from it just by putting them on my VPS. The broken links pointing to the CDN were only pdf files, so could not make big damage there, however, I could serve the malicious PDFs with for example malicious links in it or misleading information. If this CDN were used for serving the JS code for example I could do much more harm.
I reported it and was rewarded with 100$.
The final words
These types of bugs are not pretty much interesting from a technical point of view. However, as we can see they still happen due to some overlooking I think. You can find them if you’re lucky. After the bug is fixed, do not forget to remove azure resources, otherwise, you’re going to lose money. That happened to me lately.
Reward: 200 USD